
Tracker’s import and export features can help you save time with a range of activities. For example, you can move stories from a third-party tool, or archive stories and epics from a project.
Exporting stories and epics
Story and epic data can be exported to a comma-separated values (CSV) file. The exported CSV file contains column headers as the first row of the CSV file that correspond to Tracker field names. See Field names for CSV data for the fields that are exported.
Exporting selected stories
Stories can be exported from a project or a workspace to a CSV file.
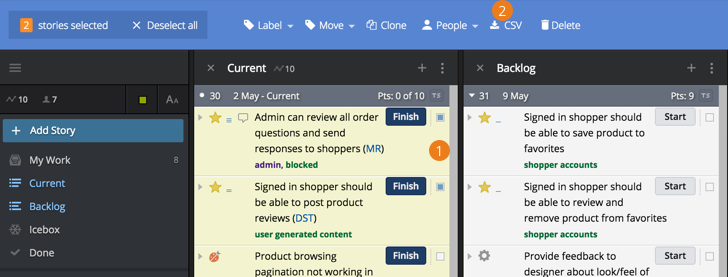
-
Select stories using the checkbox to the right of the story.
-
Choose the CSV option in the Bulk Actions menu.
A CSV file will be generated and saved to your default download location.
Exporting an entire project
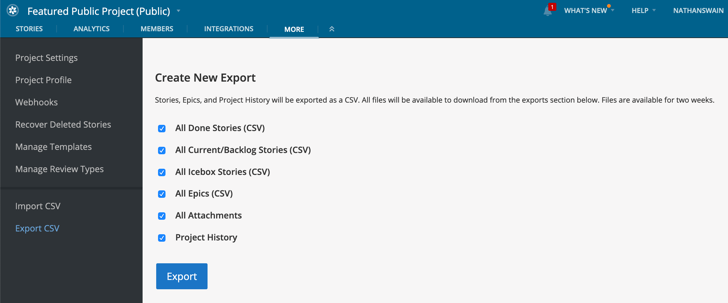
Click the MORE tab in the top nav of your Project Stories view, then choose the Export CSV option to export all stories, epics, attachments and 6 months of history in a project.
You can also select subsets of stories, including Done, Current/Backlog, or Icebox stories, as well as all Epics, File attachments and/or Project history (history is limited to 6 months).
Exporting epics from a project
Epics can also be exported using the Export CSV option in the MORE tab in the top nav (you will need to deselect all options except for Epics). All epics in the project are exported.
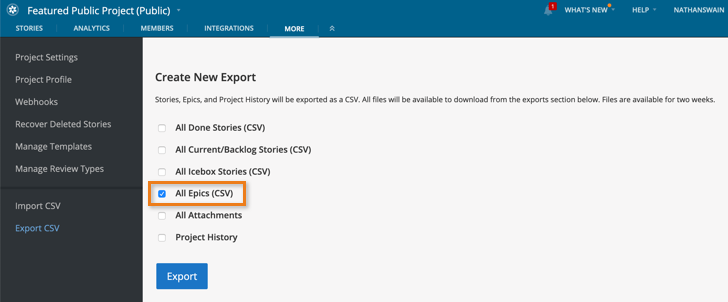
Exporting an epic does not export the stories in an epic, unless the requested export also includes stories, as described in Exporting an entire project. To export only the stories in an epic, see Exporting stories in an epic.
Exporting stories in an epic
All stories in an epic can be exported at once using panel options. Here’s how to export the stories in a single epic:
- Click the arrow on the right side of the epic preview, or click Add/View Stories from the expanded epic to show all stories in the epic in a separate panel.
- Click the Panel Actions menu at the top right of the panel, and choose Select all to select all stories in the epic.
- Choose the CSV option in the Bulk Actions menu. A CSV file will be generated and saved to your default download location.
If you would like to export only epics, see Exporting epics from a project.
Exporting data from a report
The CSV icon on a report indicates that the data in the report can be exported to a CSV file. Click
![]() to automatically download a CSV file of the report data.
to automatically download a CSV file of the report data.
Adding stories and epics via Import
Tracker has an import utility that will create new stories and epics or update existing stories and epics with CSV data. The data can reside in a file or can be pasted into the import field in Tracker.
Creating CSV data
The first row in your CSV data must contain column headers that describe the data being imported. The headers must match Tracker field names exactly. See Field names for CSV data for a list of the most commonly used fields for importing into Tracker, along with their definitions and possible values/restrictions.
For stories in any state other than accepted, Tracker orders stories in their respective panels to match their order in the file. Stories should be listed in priority order from highest to lowest.
Tracker allows 3000 stories per import. If you have more than 3000 stories, split the data into multiple files.
Accepted stories are ordered by the accepted_at date.
Importing CSV data
After you have prepared your CSV data, import the data on the Import CSV page, then do the following:
-
Go to the destination project.
-
Click MORE in the top nav, then Import CSV.
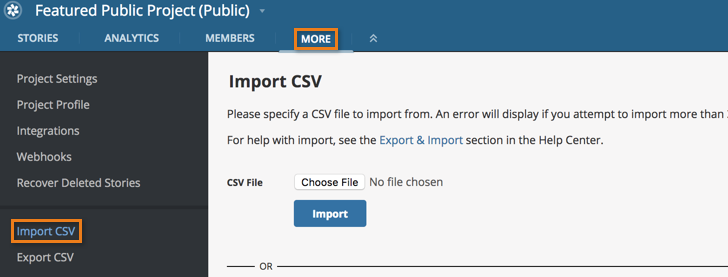
- If your data is in a CSV file, click the Choose File button and select the appropriate file. (You can also paste data that is in comma-delimited text format into the CSV text field.)
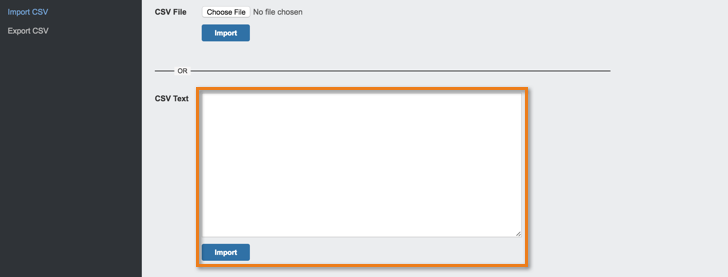
- Click Import.
Large files may take several minutes to process. Once you see the message “We’re processing this file. Feel free to navigate away:” you can leave this page and come back later to see the status and results.
If your import is successful, Tracker will display a message that tells you how many stories and epics were created.
If there are problems with your CSV data, Tracker will not process any of the data. Use the displayed error messages to correct your data and retry. See Troubleshooting import failures for helpful tips on correcting your CSV data.
Example CSV data
Importing this example results in one new story, and an update to an existing one:
Id,Title,Labels,Type,Estimate,Current State,Created at,Accepted at,Deadline,Requested By,Owned By,Description,Comment,Comment
100, existing started story,"label one,label two",feature,1,started,"Nov 22, 2007",,,user1,user2,this will update story 100,,
,new story,label one,feature,-1,unscheduled,,,,user1,,this will create a new story in the icebox,comment1,comment2
This example results in one new epic, and an update to an existing one:
Id,Title,Labels,Type,Description
100, existing epic,"label one,label two",epic,this will update epic 100
,new epic,label one,epic,this will create a new epic in the icebox
Importing this example creates two new stories and one new epic:
Title,Type,Description
first new story,, this will be the description for one new story
second new story,, and this will describe a second new story
and one epic,epic,this will be the description for one new epic
Field names for CSV data
| Column Header | Content | Possible values or restrictions |
|---|---|---|
| Title | The title of the story | There is a 5,000-character limit. This is the only required column (except when importing epics, in which case both the “Title” and “Type” columns are required). |
| Labels | Tags which you can associate to your stories | Separate multiple labels by comma. Epics may have only one label and the label must be unique. |
| Type | The type of story | Feature, bug, chore, epic, release If empty or omitted, the story type will default to feature. |
| Estimate | The numerical point value to assign to the story | The story must be of type feature. The value must correspond to the selected point scale for the project. Note: A value of “-1” indicates an unestimated story. However, if an estimate of “-1” is assigned, the state must be compatible (i.e., a feature story can’t be in the accepted state without a point estimate). Epic and releases may not contain estimates. Bug and chores may contain estimates if the Bugs and Chores May Be Given Points setting is enabled in the destination project’s settings. |
| Current State | The current state of the story | unscheduled, unstarted, started, finished, delivered, accepted, rejected If empty or omitted, the state will default to unscheduled and the story will be placed in the Icebox. Stories of type Chore can only have the following states: unscheduled, unstarted, started, accepted Stories of type Release can only have the following states: unscheduled, unstarted, accepted |
| Created at | The date the story was created (i.e., “Nov 22, 2014” or “11/22/2014) | If empty or omitted, the created date defaults to today’s date. Future dates are not allowed. |
| Accepted at | The date the story was accepted (i.e., “Jan 15, 2015” or “01/15/2015”) | Current state must equal accepted. If empty or omitted, the accepted at date will default to today’s date. Must be empty for any state other than accepted. Future dates are not allowed. |
| Requested By | The name of the user who requested/created the story | If empty or omitted, the requester will be set to the user importing the CSV file. If specified, the name must match the Tracker username exactly to be linked properly. For example, if the user’s name in Tracker is “David Smith” and the CSV file contains “Dave Smith,” then Tracker will create an uninvited usernamed “Dave Smith.” |
| Description | The content that describes the story | There is a 20,000-character limit. |
| Owned By | The name(s) of the user(s) who own the story | You can assign up to five owners, but each must be comma separated. Again, names in your CSV file must match the user’s name in Tracker exactly. |
| Comment | Comments related to your story | There is a 20,000-character limit. You can add as many comments as you like, but each must be separated into its own column. You can specify an author and date using: comment text (project member name - date) e.g. Please see the attached. (Zoe Washburne - Apr 21, 2016) |
| Task | “To-do” items related to your story | There is a 1,000-character limit. Tasks can only be added with new stories (created in the same import file as their story). Tasks cannot be added via import to existing stories. You can add as many tasks as you like, but each must be separated into its own column. Each “Task” column must be paired with a “Task Status” column. |
| Task Status | The status of your task | “completed” or “not completed” It is not possible to update the status of existing tasks. |
| Deadline | A deadline date that can be added to a story of type “release” | The story must be of type release. Future dates are allowed. |
| Blocker | Information about something blocking a story, can include a link to another story | For example: “blocked by #9999999” There is a 1,000-character limit. Blockers can only be added with new stories (created in the same import file as their story). They cannot be added via import to existing stories. Additionally, existing blockers cannot be updated or deleted via import. You can add as many blockers as you like, but each must be separated into its own column. Each “Blocker” column must be paired with a “Blocker Status” column. |
| Blocker Status | The current status of the blocker | “blocked” or “resolved” It is not possible to update the status of existing blockers. |
Updating stories and epics via Import
To update an existing story or epic, the ID of the story or epic to be updated must be specified in the import data. Add values for other fields as desired, or omit values that you do not want to change.
You can combine update data with create data in the same data set. Create data will omit a value for the ID, whereas update data will include a value for the ID. For example, the following data will create a new story and update the state of an existing story.
Id,Title,Labels,Type,Description
,new story,label one,feature,this will create a new story in the icebox
99266904,existing story,,,this will update story 99266904
Here are some additional considerations for updating stories via CSV:
- New comments, tasks or blockers cannot be added to an existing story with Import (only to new stories).
- If Requested by is empty on the existing story and not specified in the import data, the requester name will be set to the importer’s username.
- To change a story estimate to unestimated, set the Estimate column value to “-1.”
Using Export and Import to copy stories between projects
You can combine an export from one project with an import into another project to copy stories from one project to another.
Certain columns (in an exported CSV file) are ignored during import, including iteration number, start/end dates, and the URL.
Here are some additional considerations for importing data into another project:
-
If the point scales for the projects are different, the story estimates must be changed to match the destination project’s point scale.
-
If the Bugs and Chores May Be Given Points setting is different between the exported project and the destination project, the bug and chore estimates must be changed to match the setting of the destination project.
-
If the project members are different between the exported project and the destination project, the owner and requester names must be updated to match the desired members of the destination project.
-
File attachments (including Google Drive attachments), project history, and story history are not exported from the original project. (See Exporting stories and epics). These items are essentially “lost” using this method to copy stories and epics.
Importing data from another tool (e.g., JIRA)
If you are moving to Tracker from another tool and that tool allows you to export data, you can easily migrate your data to Tracker using Import. See Migrating to Pivotal Tracker from a third-party tool for information on how to prepare your exported data for import into Tracker.
Here are some additional considerations for importing data from another tool:
-
Story IDs: Tracker cannot reuse the ticket/story IDs from another tool. Remove any ID columns or fields before importing into Tracker. If you want to keep previous IDs, include the ID or a URL to the old story in a Tracker comment.
-
Additional data: Your previous tool may contain additional data fields/columns that are not compatible with Tracker’s import fields. If you wish to retain these points of data, incorporate them into the Description, Tasks, or Comments fields in your CSV data.
-
File limit: Tracker allows 3000 stories per import. If you have more than 3000 stories, split the data into multiple files. The first row of each file must include the header row.
-
Attachments: Attachments cannot be imported via CSV. Attachments from another tool will have to be uploaded manually to each story.
-
Estimates for bugs/chores: If you estimated bugs/chores in your previous tool, and also want them estimated in Tracker, enable the Bugs and Chores May Be Given Points setting for your project (otherwise you’ll receive an error when importing a file that contains pointed bugs/chores).
Troubleshooting import failures
Tracker provides helpful error messages when your data is not formatted correctly or when restrictions are not met. Error messages are displayed below the CSV text area.
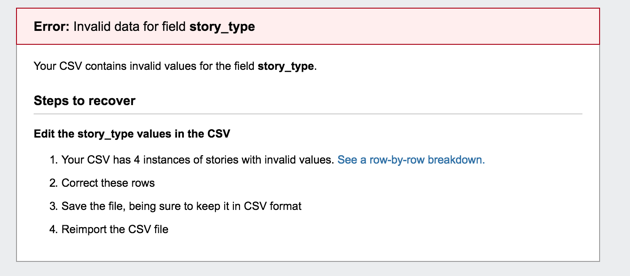
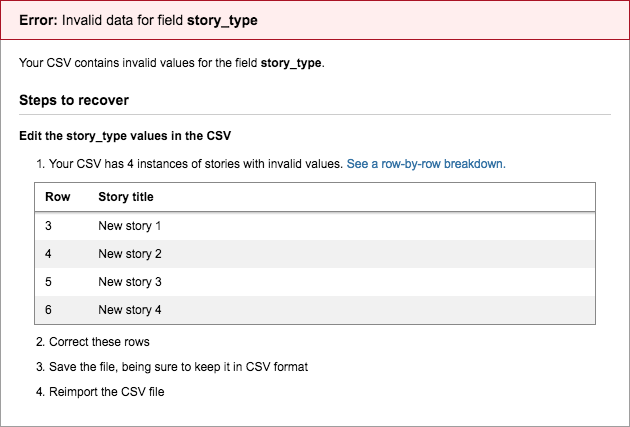
Click the link to see a row-by-row breakdown to view the row and value that needs to be corrected.
If you need additional help, please email Tracker Support with a copy of your CSV file and the ID for the destination project.