
Pivotal Tracker is an always-up-to-date tool that you leave open all day. When Tracker was young, the only way to accomplish that was some variation of HTTP polling. But the web has evolved since then, and so have the protocols. Websockets are supported by every major browser, and server-sent events are supported by most (with hacks for ones that don’t). Push technologies are a viable option for change propagation.
Tracker has many years’ worth of investment in polling infrastructure. It’s one of our most reliable endpoints. Our synchronization mechanism is based on event sourcing (which lends itself to polling very nicely). Every change you make to a project (including stories, comments, and tasks) increments its version and produces an event. Each time your browser polls, it asks for all the events (changes) since the most recent version your browser has seen. It then uses these to update its internal state. This is very bandwidth efficient because we only transmit changes instead of the entire state of your project, which can be very large, especially for established projects. This pattern is extremely robust even in the face of unreliable networks.
As we grow, we’re feeling the pain of polling for changes. Sending an HTTP request over SSL is actually quite involved. First, TCP goes through its handshake. Then, SSL goes through its handshake, before HTTP sends a request with full headers, and finally the server responds. Setting the Connection: keep-alive header helps, but we still have to send two full sets of headers plus body every time. Most of the time, the answer to your polling request tells your browser that it’s up-to-date. All that work just to do nothing.
We dreamed up a full rewrite in our lab, to unleash upon unwitting Trackers, but it was simply out of the question. Tracker is a tool that many people depend on, and even small amounts of down time are unacceptable. It’s also not very agile. We wanted to be able to quickly and transparently shut off this new solution, and go back to polling if something went wrong. Also, we wanted to do the authentication in our main Rails app so that we didn’t spread authentication and authorization logic around. Our one weird trick was our answer to these constraints.
Polling wouldn’t be so bad if we just knew when to ask the server for updates. However, it’s impossible to know without some message from the server. Push services can easily solve that. What we really need for our push MVP is just a message that tells your browser that it’s out of date and it should poll. And if we just made our polling interval longer, push could silently fail and your browser would still get updates (even if they were more delayed). And if the push server went down, we could even detect that and go back to regular polling intervals.
The next question was how to implement this. We evaluated many push protocols but settled on socket.io because of its mature client/server and protocol. After evaluating the node.js server implementation, we found it unable to meet our performance requirements with the number of VMs we were willing to throw at it. We instead chose to implement the server component in Go using some great third-party libraries like go-socket.io, redigo, and the gorilla toolkit. We wanted to keep our auth logic in Rails, which meant that we needed some way for our Rails app servers to communicate with an arbitrary amount of push servers. Ideally, Rails wouldn’t have to know about the push servers, and the push servers wouldn’t have to know about our Rails app servers. A publish/subscribe pattern fit best. Redis’ PUB/SUB facilities solved that perfectly. We ended up with something like this:
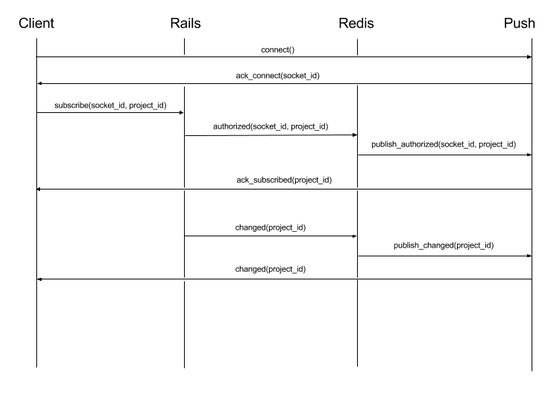
The process of rolling this out was relatively painless and quite fun. We’re currently getting a little under 30K max active connections. The Go-based server was a great decision. Its performance characteristics are predictable and reliable. Our MVP and feature flagged strategy meant a relatively stress-free rollout, as well. We even had to take down our push server for a day because of some network interruptions that exposed a concurrency bug. We received no tweets or support emails. We believe that nobody even noticed.
In the future, we want to leaving polling behind and move on to a fully push-based architecture. The main reason is simplicity. Having to maintain and monitor polling infrastructure as well as push infrastructure is operationally complex. It also means that bugs could show up in more places. This means that our one weird trick is really just a stepping stone towards eventually unifying polling and push.
We’re interested to hear your feedback. Feel free to comment here or email us.
Category: Productivity
Tags: Engineering