•
Tuesday, March 12, 2024 •
News
Pivotal Tracker subscription options are changing
We are discontinuing our ‘Startup’ and ‘Standard’ collaborator subscription plans! Read more...
We are discontinuing our ‘Startup’ and ‘Standard’ collaborator subscription plans! Read more...


Pivotal Tracker for mobile (iOS & Android), now supports two-factor authentication (2FA)! Read more...
Introducing the Standup Updates Utility (beta) for Pivotal Tracker. Read more...
Enhanced integrations and updates to promote efficient use of Tracker. Read more...

Improved features to help you organize your Icebox! Read more...

Experience “Projections”, an instrumental Analytical Tracker utility. Read more...
We’re excited to share that Pivotal Tracker is now SOC 2 Type 1 certified. Read more...
New features to help you Prioritize, Collaborate and Work Efficiently! Read more...
Plan better using Tracker’s new Analytics Projections. Read more...

We’re excited to share that Pivotal Tracker is now ISO/IEC 27001:2013 certified. Read more...

We’ve improved comment reactions to make them quicker and easier to use with your team, as well as added a prompt to help prevent accidental deletion of attachments. Read more...
The new story priority field will provide additional possibilities for categorization, sorting, and reporting as well as being an important needed element for integrating with other external tools! Read more...

Notice of new payment processor and tax collection Read more...

Labels are used heavily by Tracker users to supplement a wide array of workflow needs. As such, we’re excited to unveil a new and improved Labels panel and management experience! Read more...


Chess — the game of kings. For most, chess is a lifelong journey, a skill crafted over years of study. But, unlike most chess enthusiasts, I didn’t discover chess until well into adulthood…and several years after I jumped into the field of Product Management. However, this late discovery afforded me the chance to recognize the parallels between this ancient game and the emergent field of technology Product Management. Read more...

GDPR compliance is a beast. 99 articles, 173 recitals, 160 pages of text, and countless service providers vying to help you make sense of it all. If you’re a startup with limited resources, where and how can you even begin to make sense of it all? Read more...
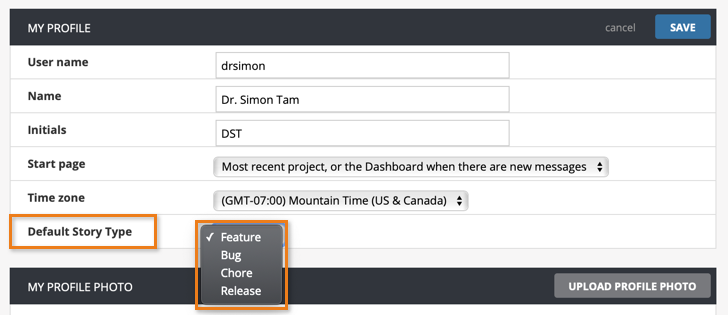
We’re happy to announce that it’s now possible to choose your preferred default story type when creating stories! Read more...
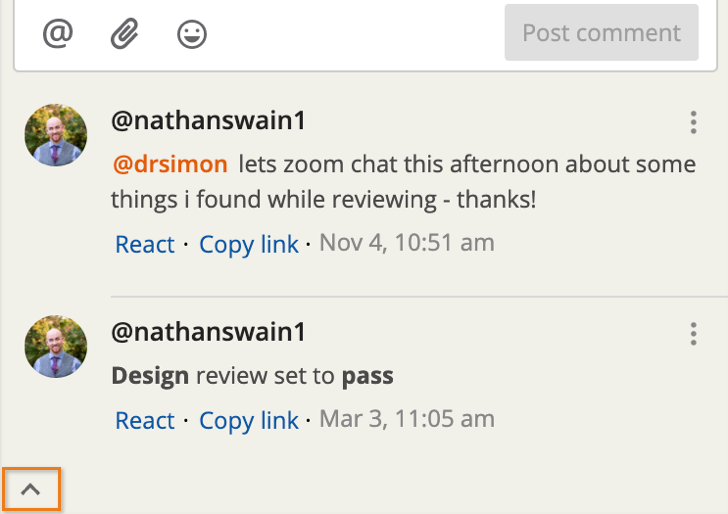
We’re happy to announce that it’s now possible to collapse and save stories from the bottom of the open story form! Read more...
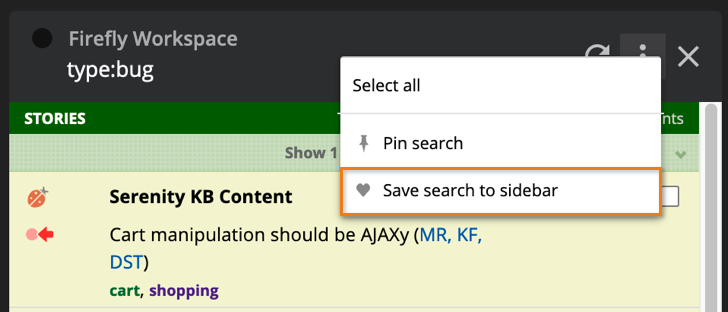
We’re happy to announce that it is now possible to save your search results to your Workspace sidebar, just as you can in individual projects! Read more...
Use Tracker on-the-go!

