
The Tracker Team spent the last week working on individual projects to improve the product. This post is the first in a series about what we did, and how it went.
We at Tracker use TDD on a daily basis to make sure the code we write is correct. We are generally pretty strict in practicing TDD, which helps catch bugs in code that appeared to be trivially correct. Because of this relatively few bugs make it past our engineers to our testers, and fewer still make it to production without notice.
A few months ago we rewrote portions of our rendering system for performance reasons. We changed from a “chunking” system where multiple stories were rendered together, to a smarter system that turned differences in arrays into the minimal viable set of DOM operations.
Our new system had sufficient tests, and performed well in simple scenarios like dragging and dropping stories. But when it came to more complicated changes like re-ordering a panel, it scrambled the results in unpredictable ways. How could this happen with such thorough test coverage?
It turns out that our tests weren’t covering all possible ordering changes. Each test looked something like this:
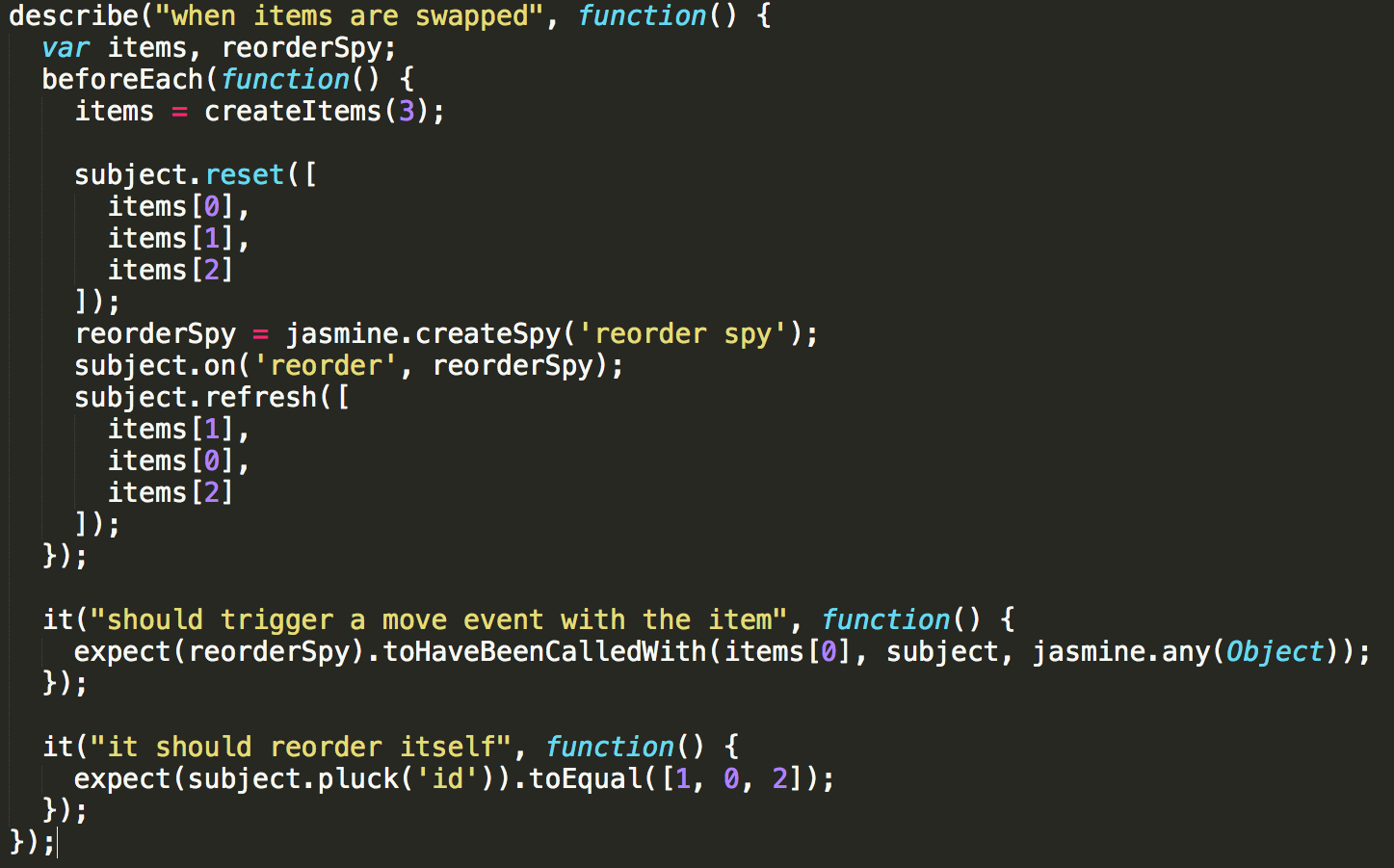
See the issue? There’s no real guarantee that a given test is exercising a sufficiently unique ordering of operations inside the subject. It’s up to the engineer to look at the tests and determine if they are covering all possible cases, which is a very difficult task.
A much better solution is something from the Functional world called Generative Tests. In a unit test, the engineer comes up with a sample set of data, and asserts that the results are as expected. In a generative test the engineer describes the shape of the data, and then defines the properties that the results should have, and the test runner provides randomized data to check against. The generative test suite I decided to use is called DoubleCheck, which is written in ClojureScript, a lisp that compiles to Javascript with the Google Closure compiler. DoubleCheck tests end up looking something like this:

Don’t be put off by the syntax, ClojureScript is simple even though it is different. The above test will be run 100 times, each time creating a non-empty vector of integers (v), then use those for testing. Variables are set up inside the “let” section using a few helper functions which are not shown. In ClojureScript (.reset subject args) is equivalent to subject.reset(args) in Javascript, and the “is” function asserts that the result is true and pretty prints any failures.
Rather than hardcoding values like [1, 0, 2], we use the provided data to drive the assertions. In this case it’s as simple as sorting the random IDs and expecting the array diffing algorithm to end up with the same order as us.
The test runner also performs what is known as “shrinking. Upon finding failing cases, the suite attempts to combine and modify the failing data in various ways to find the minimal failing case. This makes it incredibly easy to reproduce failing cases in a different environment.
For example, if I comment out the fix for the above error, the generative test returns this:
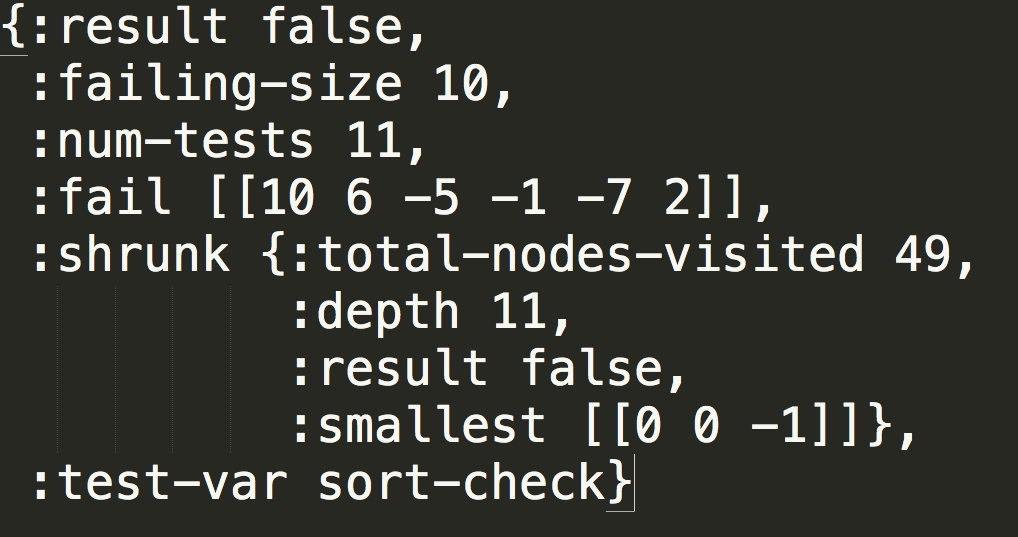
ClojureScript found 10 failing cases, which it managed to shrink down to [0 0 -1]. At this point I could either copy this data into the existing unit testing suite, or use the error messages from “is” (not shown) to hunt down the bug manually in the ClojureScript REPL.
I don’t think generative tests will ever replace unit tests. They require more thought to write, and can be tricky to run if your tests require an extensive or fragile setup. But I do think that generative tests can make a great complement to an existing unit testing suite because they are excellent at finding testing cases that you missed. And an extensive generative test suite alongside a strong unit testing suite can provide even more confidence in the correctness of your code.
Category: Productivity
Tags: Testing